Divyansh ChaudharyCoding Shorts : User Input — A Competitive Programming GuideIn my previous blog “User Input in Python with GUVI Codekata”, we saw how python handles an input from the user. Using the input()…8 min read·Oct 6, 2021----
Divyansh ChaudharyinThe StartupUser Input in Python with GUVI Codekata — A Competitive Programming GuideLike every other programming language be it C, C++, or Java we start our journey in programming with a simple “Hello World!”. This…8 min read·Oct 5, 2021----
Divyansh ChaudharyinArtificial Intelligence in Plain EnglishNaïve Bayes — The Idiot Genius of Algorithms: Machine Learning in PythonProbability and Classification is one of the most important aspect of Machine Learning. They often go hand in hand with each other. We use…5 min read·Jan 24, 2021----
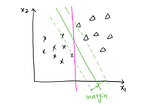
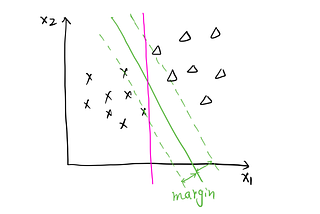
Divyansh ChaudharyinThe StartupSupport Vector Machine: Machine Learning in PythonMoving on with our knowledge from Logistic Regression — A Supervised Learning Algorithm for Classification of Data. We now study a much…5 min read·Jan 24, 2021----
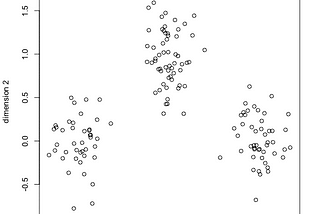
Divyansh ChaudharyinDataDrivenInvestorK-Means Clustering: Machine Learning in PythonWith our gathered knowledge from learning K-Nearest-Neighbors — KNN, which is a Supervised Learning Algorithm and a Lazy learner we found…4 min read·Jan 20, 2021----
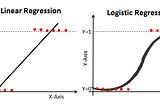
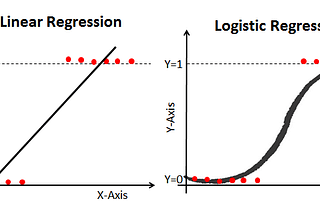
Divyansh ChaudharyinThe StartupLogistic Regression: Machine Learning in PythonFinding whether or not something will happen is another dilemma we face everyday. We are faced with the question of Yes or No all the time…4 min read·Jan 18, 2021----
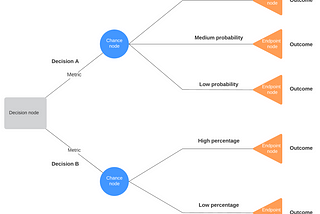
Divyansh ChaudharyinDataDrivenInvestorDecision Tree and Random Forest: Machine Learning in PythonDecisions, Decisions, Decisions… we make numerous decisions everyday; unconsciously or consciously, sometimes doing it automatically with…5 min read·Jan 14, 2021----
Divyansh ChaudharyinArtificial Intelligence in Plain EnglishK-Nearest-Neighbors : Machine Learning in PythonToday, we expect our machine to be autonomous, intelligent, and decision maker. We want them to make our lives easier and hassle free. In…5 min read·Jan 12, 2021----
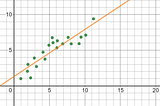
Divyansh ChaudharyinThe StartupLinear Regression: Machine Learning in PythonGetting into Machine Learning, one of the first things everyone learns is Regression. It is a Supervised Learning technique which helps us…8 min read·Jan 9, 2021----
Divyansh ChaudharyinDataDrivenInvestorWhy study Mathematics? II : Machine Learning in PythonIn this follow-up blog, we shall study about the next concept of Mathematics behind Machine Learning.6 min read·Jan 7, 2021----